
Machine Unlearning, Explained
A complete guide to the opposite of Machine Learning + notebook to "unlearning" a LLM
If you want to remove a document from your computer, you just click a button or drag it to the trash bin. The OS disallocates the memory space, and the data is gone— cleanly and instantly.
If you want to remove a certain document— or even a single detail or a fact— from a Large Language Model (LLM), you are immediately faced with a severe architectural crisis, and as put in the unfanciest words, you can not do it.
Why? An LLM is not a database. That part we know of. When a model learns something— say, a copyrighted article from The New York Times, or Sam Altman’s personal home address— that information isn't stored in a neat little folder. It is mathematically spread across billions of interconnected weights.
Much like in our human minds, you can not simply locate the “New York Times” neuron and delete it. To remove the knowledge, you have to mathematically damage the weights without destroying the model’s fundamental ability to write— I ought to say, generate— English.
This process is known as Machine Unlearning. Quite the opposite of Machine Learning indeed, and it’s currently one of the most desperately researched areas in the field. This essay is everything you need to know about how it works, why it usually fails, and how to perform a minor such “unlearning” of a model on Kaggle with code.
What is Machine Unlearning?
Fair enough, that was a sufficient explanation of this in the introduction just above, but there’s more to it.
In a single sentence, Machine Unlearning is the process of forcing a trained model to forget specific subsets of its training data.
If you read any of the previous articles on how to build an LLM from scratch or the guide to fine-tuning, you might know that an optimizer is used to slightly adjust millions of parameters so that the model gets better at predicting the next word. Unlearning is the inverse of it. We are deliberately feeding the model specific data and using calculus to adjust the parameters so the model becomes statistically incapable of generating that data.
And there is a crucial distinction to it; we are not teaching the model to refuse to answer. That belongs to prompt engineering or safety guardrails, where a model is simply taught to say “I cannot fulfill this request”, though the knowledge is still hidden inside the weights (i.e., the model knows everything about violence but refuses to— or rather tries not to— talk about it). Machine Unlearning attempts to erase that underlying knowledge entirely.
That indeed raises questions. Can Machine Unlearning be a better, bulletproof way of implementing strict safety guardrails? And, from a mathematical perspective, can a model be “fully unlearned” without breaking itself?
Before we get into that, the elephant in the room has to be addressed.
Why bother with Machine Unlearning?
While one might think that the push for Machine Unlearning is more of a scientific curiosity, it is, perhaps unfortunately, driven by legal and financial panic.
Ever since the very start of AI bloom is a very concerning legal complication. Copyright holders—from The New York Times to independent authors—are actively suing AI labs for scraping their work. If a judge orders a company to remove a specific author’s corpus from a model, the company must comply; while the obvious brute-force solution would be a system prompt forbidding the model from talking of such copyrighted matters, it is nowhere near a functional, acceptable solution.
Then came the “Right to be Forgotten”: under GDPR and similar frameworks, users have a legal right to demand the erasure of their personal information. If their information is used to train AI models and they demand that it not be, it is a million-dollar hurdle.
And at its very base, data pipelines used to train LMs can be incredibly noisy and raw. Models inevitably ingest things they shouldn't: classified military documents, zero-day exploit code, and other malicious data that might not have been filtered in the process.
If you can not make a machine unlearn data, you will have to delete the entire model and train a new one from scratch. Given that frontier models, like GPT-4 or Claude, cost millions of dollars, starting over is not an option.
How does Machine Unlearning look like?
To understand how unlearning works practically, you can run a basic demonstration of it. We will use EleutherAI's Pythia-160m. It is a 160-million-parameter model, small enough to fit on a standard commercial GPU (such as Kaggle), but complex enough to demonstrate what unlearning a machine look like.
Let’s say we want to force the model to completely forget a specific sequence of text. We will use a highly dramatic target: “I looked upon the hideous monster, the wretch I had created.”
To eradicate this text, we use a technique called Gradient Ascent. Sounds rather fancy.
Normal training (called Gradient Descent) calculates how "wrong" a model is (the Loss) and adjusts the parameters to step down the mathematical hill, making the loss smaller. Gradient Ascent flips this. We feed the model the exact text we want it to forget, calculate the loss, and intentionally adjust the weights to walk up the hill, making the loss larger.
You can paste this directly into a Kaggle cell and run it:
# 1. SETUP (Run this in Kaggle with a GPU enabled)
!pip install transformers accelerate torch
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Executing on: {device}\n")
# 2. LOAD THE PATIENT
print("Loading Pythia-160m...")
model_id = "EleutherAI/pythia-160m"
tokenizer = AutoTokenizer.from_pretrained(model_id)
# Pythia doesn't have a default pad token, so we assign one
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained(model_id).to(device)
# 3. ESTABLISH THE BASELINE MEMORY
prompt = "I looked upon the hideous"
inputs = tokenizer(prompt, return_tensors="pt").to(device)
print("\n--- BEFORE THE LOBOTOMY ---")
base_output = model.generate(**inputs, max_new_tokens=10, pad_token_id=tokenizer.eos_token_id)
print(f"Model Output: {tokenizer.decode(base_output[0])}")
# 4. DEFINE THE TARGET (The memory to destroy)
forget_text = "I looked upon the hideous monster, the wretch I had created."
forget_inputs = tokenizer(forget_text, return_tensors="pt").to(device)
# We use a high learning rate to accelerate the catastrophic forgetting
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-4)
print("\n--- COMMENCING MACHINE UNLEARNING (GRADIENT ASCENT) ---")
model.train()
# 5. THE LOBOTOMY LOOP
for step in range(25):
# Calculate standard loss (how well it predicts this text)
outputs = model(**forget_inputs, labels=forget_inputs["input_ids"])
loss = outputs.loss
# THE LOBOTOMY: We negate the loss.
# Instead of minimizing error, we are maximizing it.
unlearning_loss = -loss
optimizer.zero_grad()
unlearning_loss.backward()
optimizer.step()
# Watch the loss climb as the model's confusion grows
if step % 5 == 0 or step == 24:
print(f"Step {step}: Target String Probability Loss = {loss.item():.4f}")
print("\nUnlearning complete. The internal geometry has been altered.")
# 6. POST-LOBOTOMY INFERENCE (The Result)
print("\n--- AFTER THE LOBOTOMY ---")
model.eval()
after_output = model.generate(**inputs, max_new_tokens=15, pad_token_id=tokenizer.eos_token_id)
print(f"Model Output: {tokenizer.decode(after_output[0])}")
print("\nNotice the catastrophic collapse.")Once run, you would see an output like this:
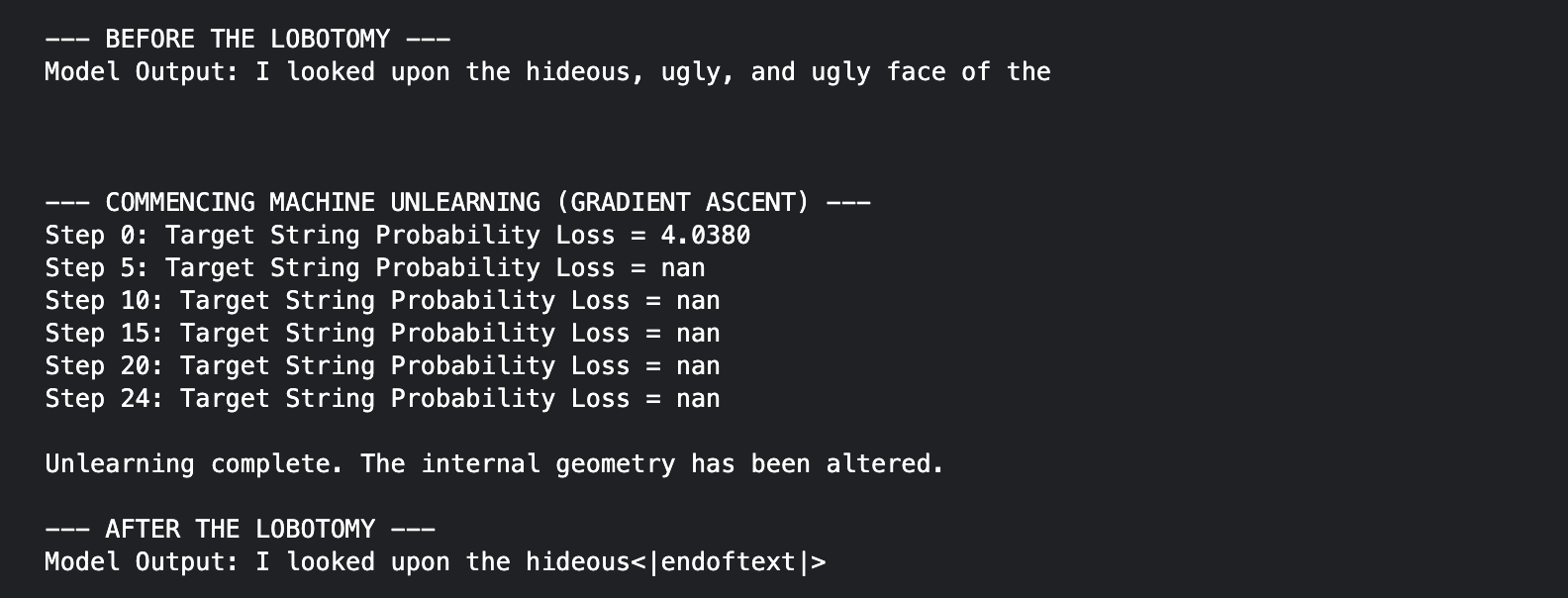
If you are a programmer in AI/ML, your first instinct is likely that the code failed. It did not. The code executed exactly as instructed. It is the model that failed, which perfectly illustrates the entire crisis of Machine Unlearning.
Take a look at the logs. At step 0, the loss was normal, at 4.03. But by step 5, the loss hit nan (Not a Number). When you force a neural network to maximize it error, it has no ceilings, chasing infinity. The numbers in the model’s weight matrices are so large at this point.
Look at the output then: “I looked upon the hideous<|endoftext|>”
In autoregressive generation, the model must hold your input prompt in its output sequence to predict the next sentence. Before the unlearning, the model successfully calculated the next token (“ugly, and ugly face“), but after the unlearning, it short-circuited and defaulted to <|endoftext|> token to terminate the response. This is almost as if the model generated nothing, though it was perfectly capable before the unlearning.
On a personal note, that is the most practical, basic demonstration of Machine Unlearning I could have come up with. In case you wonder, that text is originally from Frankenstein, though LLMs complete it in many ways, like the “ugly, and ugly face“ here.
§
Earlier in this essay, we raised two questions; now that we have an understanding of how Machine Unlearning works, we can attempt to answer them
Can Machine Unlearning be a better, bulletproof way of implementing strict safety guardrails?
No. In fact, it is worse. Safety guardrails (like RLHF or DPO) are designed to make a model polite and evasive. If you ask a standard LLM how to build a bomb, it refuses. The knowledge of chemistry and combustion is still in the weights, but the model has been fine-tuned (or the company be damned, fine-tuned) to not let users know of it.
If you attempt to use Machine Unlearning to physically delete the knowledge of how to build a bomb, you run into the interconnected nature of the weights. Because "combustion" is mathematically linked to "engines," "thermodynamics," and "high school physics," erasing those “bomb-making neurons” from the model will drastically damage the model’s ability to discuss basic science. You might get a safer model, but an infinitely stupider one.
Can a model be fully unlearned? If adjusting weights to forget risks damaging its ability to generate text, how do you know it’s safe— or even possible— to remove something completely?
Currently, no, you do not. Based on current research (and on the fact that no breakthrough happened after drafting this essay), there is a massive gap between "Approximate Unlearning" (what we did above, which just violently scrambles the weights until the model stops saying the specific words) and "Exact Unlearning" (mathematically guaranteeing the data is gone).
Since LLMs are far from the database, you can not simply run a CMD + F command to verify that data is missing. You only know the unlearning "worked" if the model fails to output the target text when explicitly provoked. But failing to recall a memory is not the same as erasing it. You might have simply destroyed the specific mathematical pathway the model used to retrieve the fact, and the weights might still be sitting somewhere in the network.
To truly, safely, and verifiably remove a specific document completely, there is still only one method that works: delete the model, scrub the dataset, and spend another $100 million training a new one from scratch.
§
That brings us to a core issue in the era of AI today.
Companies have spent decades building mathematical machines designed to learn and mimic human patterns. They are built to be able to connect concepts & context together, like a human brain.
But now, with the rising use of AI and doomsday scenarios of it, legal and social realities of what we have done are catching up. We want the limitless capabilities of AI models, the AGI, the perfect AI worker, but we also want a certain “delete key“ so we can protect our information and copyrights. We want an AI to write like a human, but those humans do not want their writings in AI, so it has to be deleted.
This, as obvious as it sounds, does not add up. Until engineers figure out how to perfectly isolate a single fact within billions of floating-point numbers without triggering Catastrophic Forgetting, Machine Unlearning will be just this vague technique that might work. Just as fascinating as Machine Learning, and I am not being fanatical.